
티스토리 뷰
Table of contents
0. Introduction
1. The procedure of scrapping data
2. The main procedure for making a web scrapper
3. Save to CSV file
4. Error history
5. Conclusion
6. References
Introduction
비즈니스 영역에서 활용도가 높은 스크래퍼를 직접 만들어보았다. 이번 글은 Python을 사용하여 Web Scrapper를 구현하는 과정 중 Back-end 작업에 해당하는 핵심적인 내용을 정리하였다.
The procedure of scrapping data
웹 스크래퍼를 구현하기 위해 스크래퍼가 어떻게 웹사이트에서 데이터를 가져오는지 개념 정리가 필요하다. 우선, 스크랩하고자 하는 웹사이트의 URL을 준비한다. Python의 request 라이브러리를 사용하여 웹의 html을 모두 가져온다. 가져온 html의 text 중에서 page의 개수를 추출한다. 이때, 가져온 텍스트를 파이썬 객체로 변환하기 위해 Beautiful Soup 패키지를 사용한다. 이런 방법으로 html 코드 중에서 필요한 부분을 추출하여 Data-set을 만든다.
Requests
Python용 HTTP 라이브러리로, requests 모듈의 함수를 사용하여 웹사이트에서 데이터를 가져온다.
Beautiful Soup
html에서 추출한 텍스트 데이터를 객체 형식으로 변환하여 결과물을 프론트에 탑재할 수 있도록 해준다.
The main procedure for making a web scrapper

맨 처음 계획한 것은 4가지 Sites의 데이터를 가져오는 것이었고, Job title은 Data Analyst, Location은 Seoul로 설정했다. (직무 이름은 추후 사용자에게 입력받은 타이틀에 해당하는 데이터를 가져올 수 있도록 바꿔줄 수 있다.) 또한, SQL을 포함한 공고만 가져오도록 하려고 했는데, 이 부분은 조금 더 탐구가 필요할 듯하여 일단 O, X로 출력하도록 처리했다. 그리고 전체 Job 중에 중복되는 공고라고 판단되는 경우 Unique한 공고만 Counting하여 진짜 Opportunity가 몇 건인지 알 수 있는 기능을 추가하려고 했다. (이 부분은 추후 Pandas를 사용하는 것이 좋을 것 같다.) 이번 글에는 이 과정을 다 담지는 않았고, 일단 indeed만 작업하는 것을 담았다. 생각보다 작업 시간이 많이 걸린다. 아마 한 번 틀을 잡아두면 다른 사이트 작업에는 시간이 단축되지 않을까 싶지만, 해 봐야 알 수 있을 것 같다.

사이트의 Page 수를 불러오기 위해 html 중에서 pagination을 찾는다. (이렇게 필요한 항목에 해당하는 html 코드를 찾을 때 해당 부분에서 마우스 우클릭 Inspection(검사)을 하면 더욱 쉽게 찾을 수 있다.)

requests와 beautifulsoup을 사용하여 html의 내용을 불러오고, pagination에 해당하는 부분에서 찾은 데이터에서 Page를 리스트에 담아준다. 맨 마지막 데이터는 다음으로 넘어가는 버튼에 해당하기 때문에 제외시킨다.
앞서 request와 beautifulsoup을 사용하여 필요한 데이터를 가져왔듯이, Job Title, Location, Company Name, Link에 해당하는 데이터를 가져오도록 한다. (indeed는 다른 채용사이트에서 정보를 가져와 일부분만 보여주고 있고, 채용 건에 지원을 하려면 다른 페이지로 넘어가도록 되어있다. --> 수정 : 모든 채용 공고마다 동일하게 보여지는 것이 아니라, 어떤 공고는 바로 다른 채용 페이지로 연결되고, 어떤 공고는 인디드 내에서 채용 전문이 보여진다.)
내가 추가적으로 적용한, 채용 공고에 SQL 포함 여부를 판별하는 부분에 대하여 이야기해 보겠다. 앞서 언급했듯이 indeed도 일종의 Scrapper Site이기 때문에 Job Posting의 전문을 보려면 다른 채용사이트로 이동해야 하는 경우가 있다. 상세 채용 정보 중 SQL 포함 여부를 체크하고 해당되면 O, 아니면 X를 Dictionary에 추가하도록 하였다. (Data Analyst 직군에서 Excel만 요구하는 공고들이 있기 때문에 그런 공고는 걸러내고자 한 것이다.) 이 과정에서 각각 채용 공고의 전문이 담긴 페이지를 하나씩 체크해야 하기에 아무래도 결과를 출력하는데 시간이 더 많이 걸렸다. 200여 개 판별하고 가져오는데 1~2분 걸린다. 그래도 사람이 일일이 확인하는 것보다는 비교가 안 되게 빠르다.
Save to CSV file
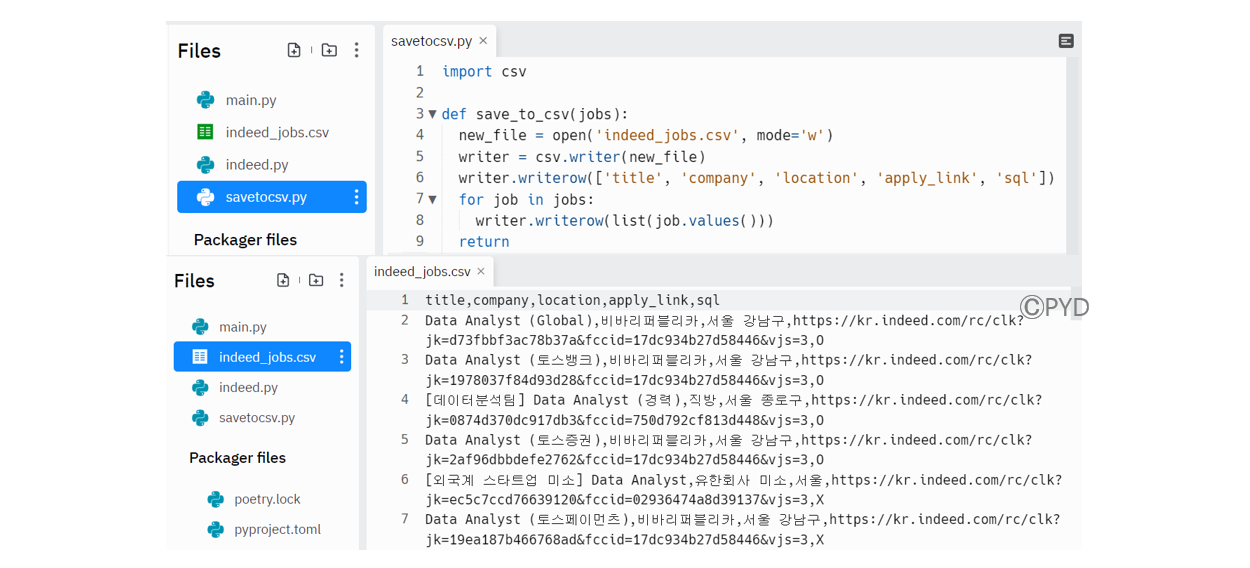
웹에서 스크래핑해 온 데이터를 csv 파일로 저장할 수 있다. Dictionay 형태로 되어 있기 때문에 각 Key에 해당하는 Value만 가져와서 List로 반환할 수 있도록 해준다. for문을 사용하여 모든 리스트를 csv 파일에 writing해주면 된다.
Error history
1) replit error
코드가 분명 정상인데 replit에서 실행 시 NoneType Error가 발생해서 코드를 이리저리 바꿔가며 해결해 보려고 시도했다. 결론은 코드에는 문제가 없고, replit에서 에러가 나는 듯했다. 스크랩할 페이지를 1개씩 돌려보니 처음 실행 시에는 None으로 출력되어 에러가 나고, 동일한 코드 그대로 두고 다시 실행시키면 제대로 값을 불러온다. 또는 title, company 등의 항목 하나씩 테스트하면 잘 불러오는데, 항목별 연달아 실행하도록 전체 테스트를 하면 불러오다가 에러를 발생시켰다.
에러 추가, replit에서 잘만 불러오던 beautifulsoup4 패키지를 import 하지 못하는 Error가 발생하기 시작했다. 잘만 되던 게 갑자기 되지 않으니 이것 또한 replit의 문제로 보였고, repl을 새로 생성하여 주니 bs4 import 문제와 앞서 발생했던 NoneType Error도 모두 깔끔하게 해결되었다. 이건 코드의 문제가 아니라 replit의 문제인 것이 분명하다.
2) 예외 상황 발생
아래 예시처럼 indeed 페이지에는 아무 내용이 없고, 원본 공고로 이동해야 전체 내용을 볼 수 있는 경우에 발생할 수 있는 예외 상황을 발견했다. 내용을 텍스트로 작성한 것이 아닌 통 이미지로 올려놓은 경우이다. 이건 indeed에서만 발생할 수 있는 문제가 아니고, 다른 채용 사이트에도 이런 경우(통 이미지)가 있을 수 있다. 이런 경우에는 처리 방법을 여러 가지 구상할 수 있을 것인데, 아예 리스트에 추가되지 않도록 하던지, sql 판별 항목에서 다른 처리를 할 것인지 등을 생각해 볼 수 있겠다. 그냥 데이터를 가져오기만 한다면 문제가 없겠지만 특정 항목 충족 여부를 추가하려니 고려해야 할 사항이 훨씬 많아진다.

Conclusion
이번 글에서는 웹에서 데이터를 어떻게 가져올 수 있는지에 중점을 두었다. 파이썬 웹 스크래퍼를 구현해 보니 어려운 작업이라기보다는 귀찮은 작업이라고 생각된다. 자잘한 오류를 해결하는 과정에서 시간이 많이 걸린다. Front-end 작업은 급하지 않기에 좀 여유를 두고 해 보려고 한다. 이번 Side-project로 Web에 대한 이해가 더욱 넓어질 수 있었다. (Special thanks to Nicolas!)
References
Requests Library https://docs.python-requests.org/en/latest/
Beautiful Soup https://beautiful-soup-4.readthedocs.io/en/latest/
Nomad Coder https://nomadcoders.co/
보던 글 목록 : 브라우저 뒤로 가기 메인 화면 : 좌측 상단 아이콘
🍍 I am becoming AI expert who can develop cool things by coding.